เกริ่นนำ :
ลองเขียน Data Series วันละตอนเนาะ
ครบ 1 ปีน่าจะมี 365 เรื่อง ^^
เป็นเรื่องสั้นๆ อาจจะไม่ยาวมากนะครัช
แต่อ่านแล้วน่าจะเห็นภาพ และการนำไปใช้งานได้บ้าง
==================
ว่าด้วยเรื่องของการวัดระยะ
==================
คงปฎิเสธได้ยากในการทำงานสาย Data
ว่าในแทบทุกวันเรามักจะอยู่กับข้อมูล
และข้อมูลเองก็มีทั้งชนิดที่เป็นทั้งตัวเลข และไม่ใช่ตัวเลข
แน่นอนว่าเพื่อนๆอาจจะคุ้นกับข้อมูลที่เป็นตัวเลขกัน
ซึ่งข้อมูลที่เป็นตัวเลข เราก็คงคำนวณได้ไม่ยากนัก
หรือสามารถคำนวนใจใจได้เลย
เช่น
นาย A โทรศัพท์ นาน 2 นาที
นาย B โทรศัพท์ นาน 2 นาที 1 วินาที
นาย C โทรศัพท์ นาน 1 นาที
ก็แสดงว่านาย A และ นาย B มีความใกล้กันในมุมมองของเวลาที่ใช้ในการโทรศัพท์
แต่กลับกัน
นาย A และ นาย B มีความไกลกันจากนาย C ในมุมมองของเวลาที่ใช้ในการโทรศัพท์
ทีนี้ถ้าข้อมูลไม่ใช่ตัวเลข เราจะคิดอย่างไรดี !?
ก็คงต้องหา logic ต่างๆมาช่วยหาคำตอบเช่น
หากข้อมูลที่เรามีเป็นแบบนี้
นาย A ซื้อสินค้า { แอปเปิ้ล }
นาย B ซื้อสินค้า { ส้ม, กล้วย }
นาย C ซื้อสินค้า { แอปเปิ้ล, ส้ม }
โดยที่เราสนใจเฉพาะการเกิดของสิ่งของที่ถูกซื้อ
ถ้าเราแทน { แอปเปิ้ล, ส้ม, กล้วย }
ด้วยตัวเลข [ 1, 1, 1 ]
โดยที่เลข 1 แสดงถึงการซื้อสินค้าตำแหน่งนั้นๆไปและเลข 0 แสดงว่าไม่พบข้อมูลการซื้อสินค้าชนิดนั้นๆเราสามารถจัดรูปการเขียนได้ใหม่เป็น
นาย A ซื้อสินค้า [ 1, 0, 0 ]
นาย B ซื้อสินค้า [ 0, 1, 1 ]
นาย C ซื้อสินค้า [ 1, 1, 0 ]
แล้วเราจะวัดอย่างไรต่อดีน้าา !???
=============
Hamming Distance
=============
Hamming Distance เป็นเครื่องมือวัดระยะรูปแบบหนึ่ง
ที่ช่วยเราวัดข้อมูลที่มีลักษณะเป็น Binary Vector หรือ { 0, 1 }
(คือมีข้อมูลแค่ 2 ชนิด ศูนย์ และหนึ่ง)
ดูแล้วก็คล้ายๆกับเลขบิทหรือเลขฐานสองเลยเนาะ !
โดยวิธีการวัดความใกล้กันนั้น
ถ้าข้อมูลของนาย X = [ 1, 1, 1 ]
ถ้าข้อมูลของนาย Y = [ 1, 1, 1 ]
ดูด้วยตาก็คงเทียบได้เลยว่าตรงกันเป๊ะๆ
มี 1 เหมือนกันทั้งค่า และตำแหน่ง
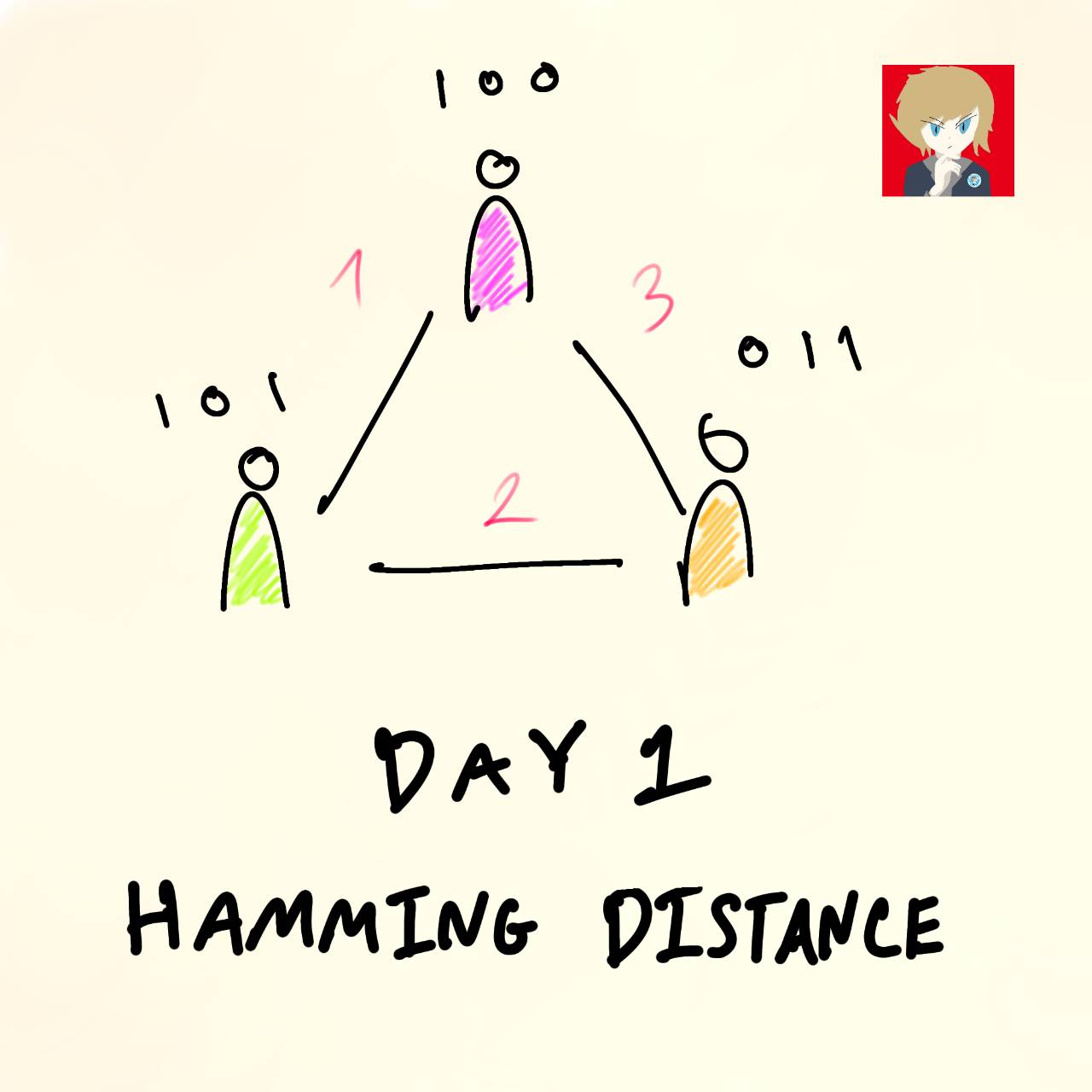
ทีนี้กลับมาดูกันที่ความห่างกันของ นาย A และนาย B กันบ้าง
นาย A = [ 1, 0, 0 ]
นาย B = [ 0, 1, 1 ]
เริ่มต้นโดยทำการ Check ทีละตำแหน่งว่ามีตัวไหนต่างกันบ้าง
ปรากฎว่า ต่างกันทุกตำแหน่งเลย !!!
นาย A, นาย B ต่างกัน = 3
ลองคำนวนทั้งสามคนดู
นาย A, นาย C ต่างกัน = 1
นาย B, นาย C ต่างกัน = 2
ตอนนี้เราก็รู้ละว่าแต่ละคนมีระยะห่างกันเท่าไหร่
นาย A, นาย B ต่างกัน = 3
นาย A, นาย C ต่างกัน = 1
นาย B, นาย C ต่างกัน = 2
ดังนั้นหากเรา เพิ่มการคำนวนเล็กน้อยลองคิดเป็น %
ความเหมือนเราก็สามารถหาได้โดยหาค่าเฉลี่ยความแตกต่างก่อน
โดยนำจำนวน Items ทั้งหมดมาหาร
นาย A, นาย B ต่างกัน = 3/3
นาย A, นาย C ต่างกัน = 1/3
นาย B, นาย C ต่างกัน = 2/3
จะได้
ความแตกต่างโดยเฉลี่ยต่อตำแหน่ง
นาย A, นาย B ต่างกัน = 1.00
นาย A, นาย C ต่างกัน = 0.33
นาย B, นาย C ต่างกัน = 0.66
เราคิดเป็น % ความเหมือนหรือความใกล้กันโดยนำ 1 มาลบ แล้ว คูณ 100
จะได้
นาย A, นาย B เหมือนกัน = 0.00 %
นาย A, นาย C เหมือนกัน = 66.6 %
นาย B, นาย C เหมือนกัน = 33.3 %
และจากประโยชน์ดังกล่าว
เราเองก็สามารถนำไปใช้งานในมุมมองอื่นๆต่อได้อีกเยอะเลย
อาทิเช่น
– การจัดกลุ่มลูกค้า
– การค้นหาคนที่มีพฤติกรรมเหมือนกลุ่มใดกลุ่มหนึ่ง
– การนำเสนอสินค้าที่ใกล้เคียงกับคนแต่ละกลุ่ม
– การแนะนำสินค้าโดยอิงจากความใกล้เคียงกันของกลุ่ม
– การส่งแคมเปญการตลาดให้แต่ละกลุ่ม
– การทำโปรไฟลล์ลูกค้า
– ใช้เป็น 1 ใน ตัววัดประสิทธิภาพโมเดลในโจทย์ปัญหา Multilabel-Classification
– ใช้วัด Error จากการสื่อสาร
– และอื่นๆอีกมากมาย
=========================
ขอบคุณทุกท่านที่ติดตามครับ
ฝากไลค์ แชร์ คอมเมนท์ เพื่อเป็นกำลังใจ
Made with Love ![]() by Boyd
by Boyd
=========================
Series นี้ออกแบบมาให้เพื่อนๆที่สนใจในเรื่องของ Data
หรือเพื่อนๆที่ทำงานสาย Data แต่มีเวลาจำกัดได้อ่านกันครับ
โดยเนื้อหาอาจจะมีสลับกันไปทั้งในเรื่องของความง่าย และยาก
รวมถึงเนื้อหาที่หลากหลายทั้ง Coding, Math, Data, Business, และ Misc-
Feedback กันเข้ามาได้นะครับ ว่าชอบหรือไม่ชอบอย่างไร
เพื่อการปรับปรุง Content ให้ดียิ่งขึ้น
– หากผิดพลาดประการใดต้องขออภัยมา ณ ที่นี้ด้วยนะครับ
– ท่านใดมีประสบการณ์การใช้งาน สามารถแชร์ให้เพื่อนๆอ่านได้เลยนะครับ

ความคิดหนึ่งเกี่ยวกับ “Day 01 – Hamming Distance”