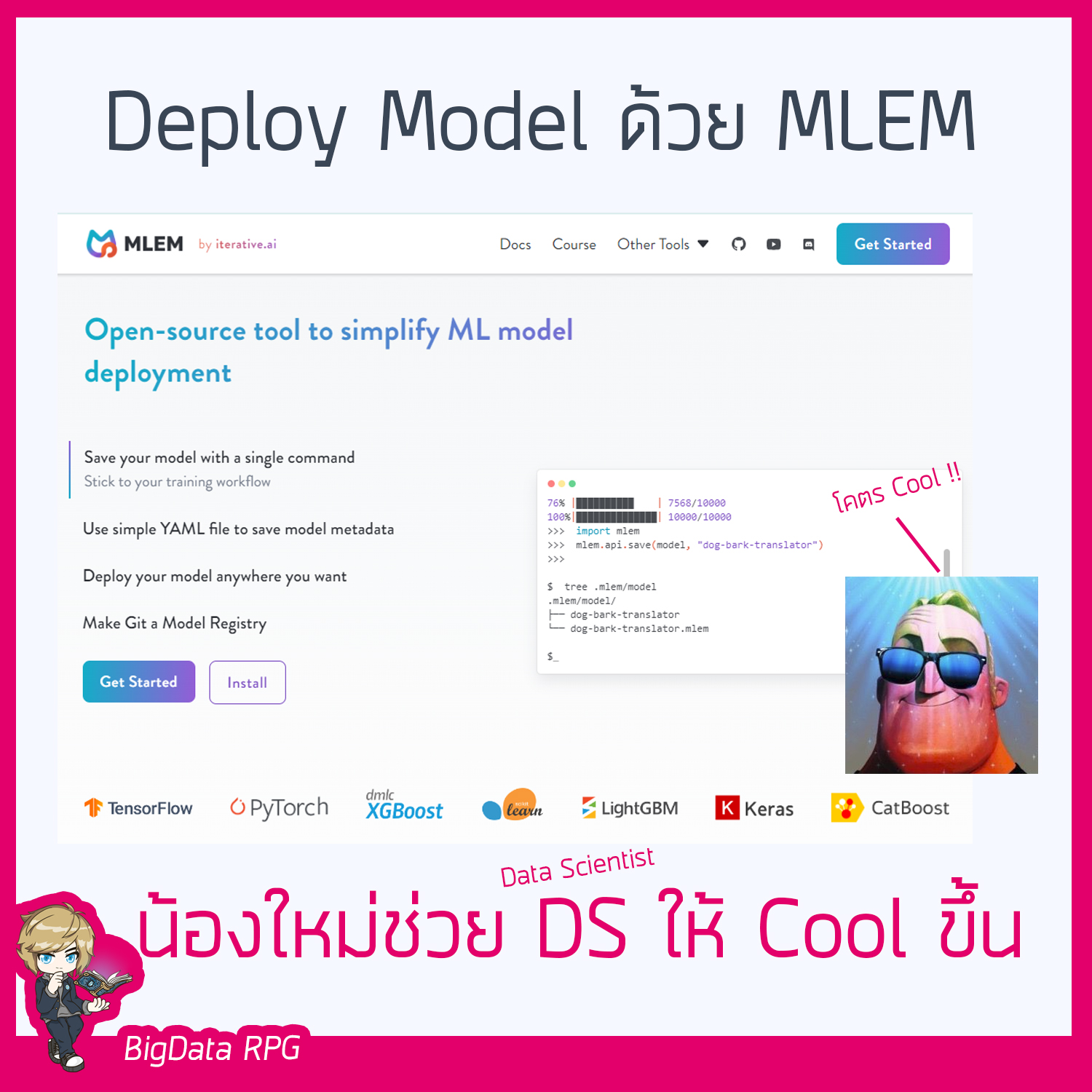
Deploy ML model ด้วย MLEM ❤️น้องใหม่ ที่ช่วยให้งาน DS งอ่านเพิ่มเติม “Deploy ML model ด้วย MLEM”
หมวดหมู่ คลังเก็บ: Data Science
Missing Values คืออะไร

“ถ้าคุณเติม Missing Value ผิดวิธีมันจะกลายเป็นการเพิ่ม อ่านเพิ่มเติม “Missing Values คืออะไร”
เริ่มต้น Bayesian ด้วยเล่มนี้

ชวนอ่านหนังสือน่ารั้กๆเบาๆกันบ้าง ❤️🐣เพื่อนๆที่ชอบสาย Bอ่านเพิ่มเติม “เริ่มต้น Bayesian ด้วยเล่มนี้”
Data Leakage คืออะไร

ไปเที่ยวสันเขื่อนกัน ม๋ายยยย !!!! 🙈 วันนี้พามารู้จักกับอ่านเพิ่มเติม “Data Leakage คืออะไร”
ชวนอ่าน Probabilistic ML

ไม่ไหวบอกไหว ! ชวนอ่าน ML สาย Prob กัน หยุดยาวแบบนี้พวกอ่านเพิ่มเติม “ชวนอ่าน Probabilistic ML”
ป. ตรี-โท Data Science ในไทย

ป. ตรี-โท ในไทยมีที่ไหนบ้างน้าาที่สอน Data Scienceบอยด์อ่านเพิ่มเติม “ป. ตรี-โท Data Science ในไทย”
เรียนสถิติกับ Cassie Kozyrkov

สถิติ เป็นเรื่องเข้าใจยาก หรือเพราะ เราหาคนที่อธิบายให้อ่านเพิ่มเติม “เรียนสถิติกับ Cassie Kozyrkov”
เพิ่มรายได้จาก Kaggle Survey 2021

มาเพิ่มทักษะและรายได้ในสาย “Data Scientist” กันจากผลสำรอ่านเพิ่มเติม “เพิ่มรายได้จาก Kaggle Survey 2021”
Day 07 – Haver Distance!

I am writing the data series daily1 year we will have 3อ่านเพิ่มเติม “Day 07 – Haver Distance!”
Day 06 – Levenshtein Distance

I am writing the data series daily1 year we will have 3อ่านเพิ่มเติม “Day 06 – Levenshtein Distance”
