
แนะนำงาน MLOps Summit เข้าฟังฟรี ❤️🐣MLOps Day 2 Summit:อ่านเพิ่มเติม “MLOps Summit เข้าฟังฟรี”
หมวดหมู่ คลังเก็บ: Machine Learning
Deploy ML model ด้วย MLEM
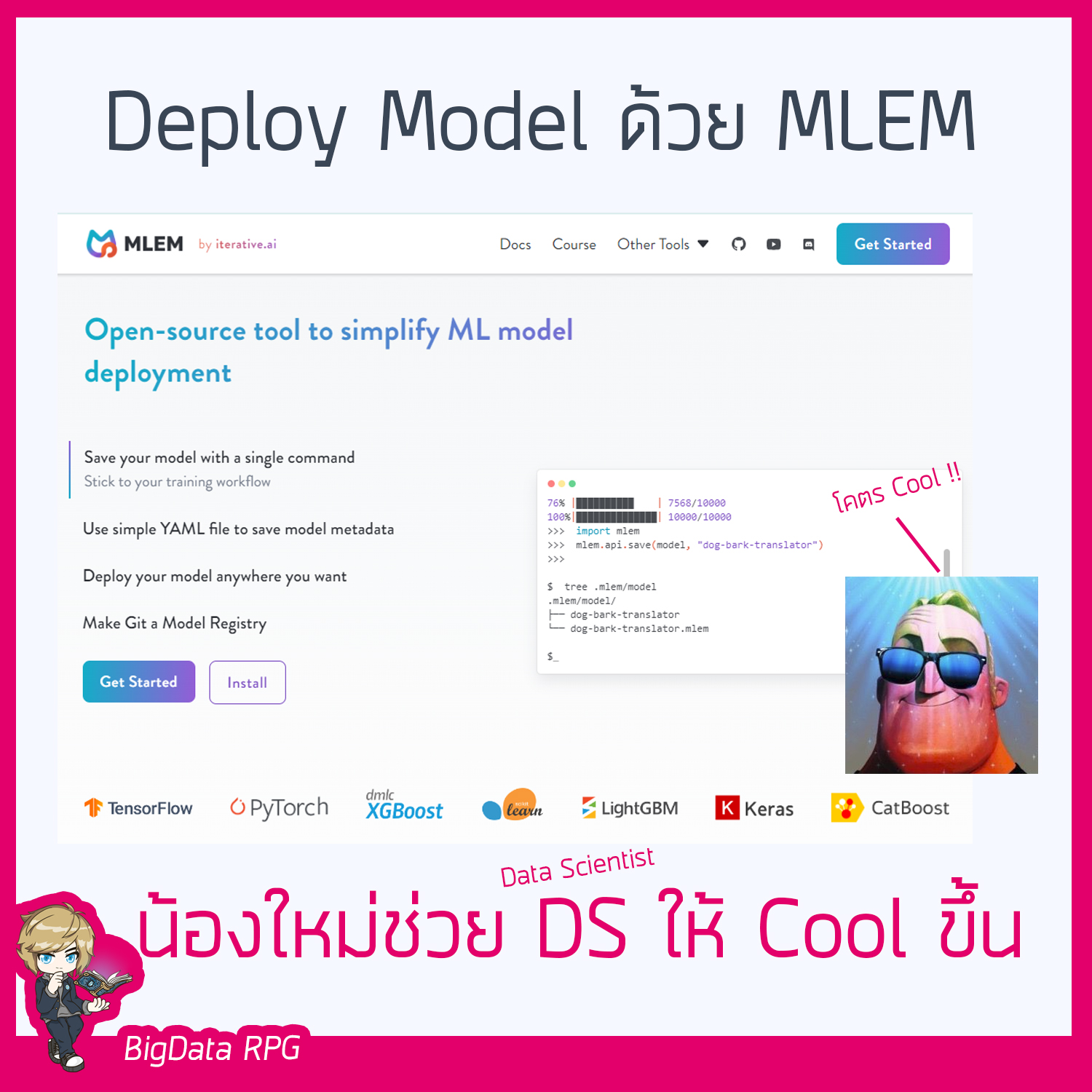
Deploy ML model ด้วย MLEM ❤️น้องใหม่ ที่ช่วยให้งาน DS งอ่านเพิ่มเติม “Deploy ML model ด้วย MLEM”
เรียน ML/RL ฟรี โดย AWS

เรียน ML และ RL ฟรี โดย AWS ! ❤️🚀จากโครงการ AWS DeepRacอ่านเพิ่มเติม “เรียน ML/RL ฟรี โดย AWS”
พาเพื่อนๆมารู้จักกับ Feature Stores
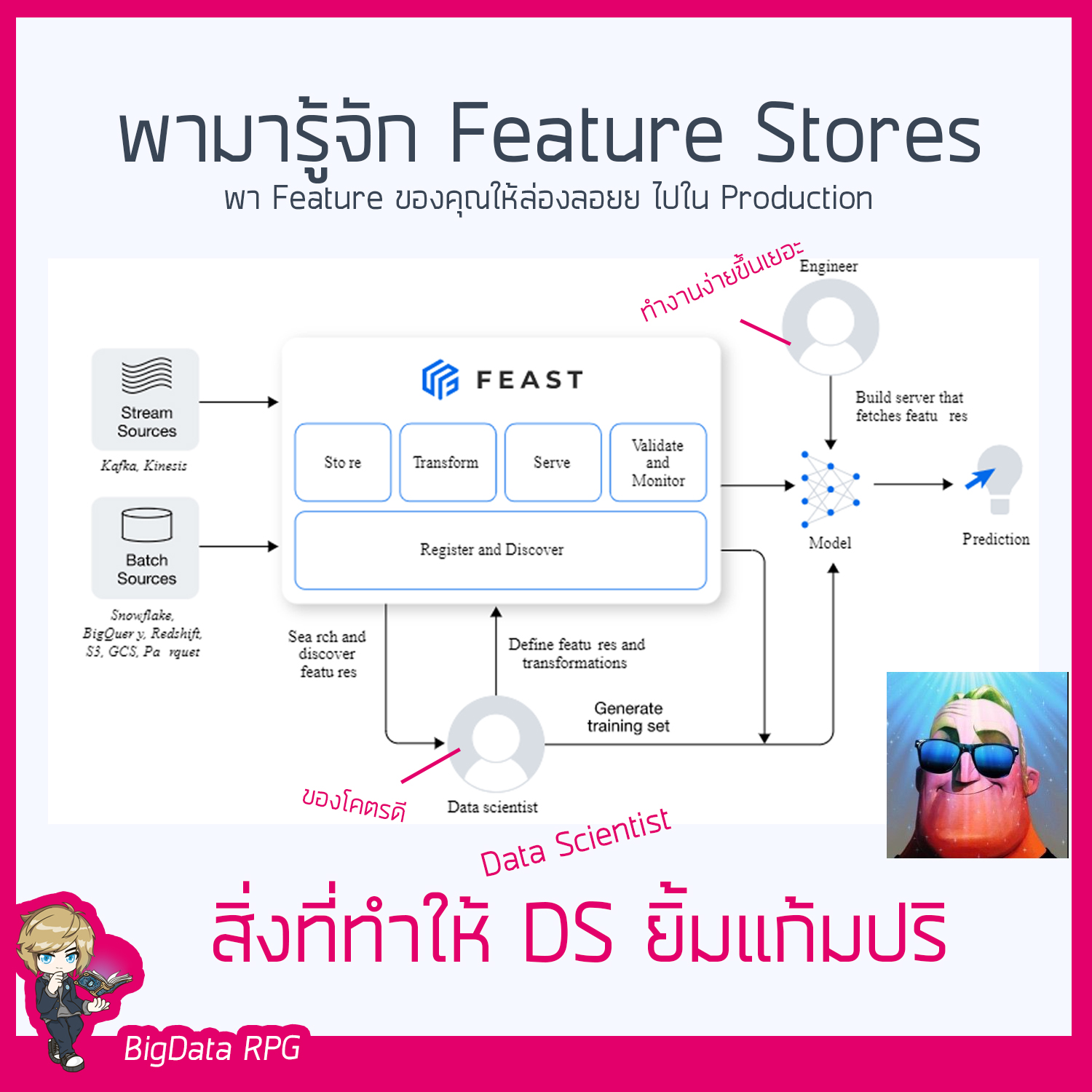
พาเพื่อนๆมารู้จักกับ Feature Stores 👷♀👩🔬เพราะ Model Mอ่านเพิ่มเติม “พาเพื่อนๆมารู้จักกับ Feature Stores”
ชวนดู Data@Scale

คืนนี้ชวนอดนอนชม Data@Scale 🌹 (5ทุุุ่ม แจกัน)Conferenceอ่านเพิ่มเติม “ชวนดู Data@Scale”
เริ่มต้นศึกษา MLOps

👷♀ แนะนำช่องเริ่มต้นศึกษาสาย MLช่องนี้เลย DataTalksCluอ่านเพิ่มเติม “เริ่มต้นศึกษา MLOps”
เริ่มต้น Bayesian ด้วยเล่มนี้

ชวนอ่านหนังสือน่ารั้กๆเบาๆกันบ้าง ❤️🐣เพื่อนๆที่ชอบสาย Bอ่านเพิ่มเติม “เริ่มต้น Bayesian ด้วยเล่มนี้”
Data Leakage คืออะไร

ไปเที่ยวสันเขื่อนกัน ม๋ายยยย !!!! 🙈 วันนี้พามารู้จักกับอ่านเพิ่มเติม “Data Leakage คืออะไร”
ชวนอ่าน Probabilistic ML

ไม่ไหวบอกไหว ! ชวนอ่าน ML สาย Prob กัน หยุดยาวแบบนี้พวกอ่านเพิ่มเติม “ชวนอ่าน Probabilistic ML”
Uplift Model คืออะไร !! ทำไม Data Scientist ต้องรู้

จะรู้ได้อย่างไรว่า คนนี้ซื้อ คนนี้ไม่ซื้อ คนนี้ไม่สนใจ อ่านเพิ่มเติม “Uplift Model คืออะไร !! ทำไม Data Scientist ต้องรู้”
