
รีวิวสอบภาษาอังกฤษซักหน่อย ตัวที่บอยด์สอบเรียกว่าDuolinอ่านเพิ่มเติม "รีวิวสอบวัดระดับภาษาอังกฤษ"
แก้ปัญหาดองหนังสือ !!!

พึ่งค้นพบวิธีอ่านหนังสือให้จบไวขึ้น ต้องเกริ่นก่อนว่าเปอ่านเพิ่มเติม "แก้ปัญหาดองหนังสือ !!!"
Review ปี 2021

Review ปี 2021 ที่ผ่านมางับ ขอบคุณอีกปีที่ได้เติบโตขึ้นอ่านเพิ่มเติม "Review ปี 2021"
เรื่องสยอง 2 บรรทัด

ในความเป็นจริง ถ้าเราเลือกได้เราคงไม่อยากเลือกผิด ! ในชอ่านเพิ่มเติม "เรื่องสยอง 2 บรรทัด"
ปี 2020 กับ Skills ของ Data Scientist ที่ต้องเจอ

หยิบกระดาษขึ้นมาแล้วทำ Checklist กันได้เลย. 📚 1. Mอ่านเพิ่มเติม "ปี 2020 กับ Skills ของ Data Scientist ที่ต้องเจอ"
10 ข้อศิลปะการปรับปรุง AI Products แบบ 100x
“เคยสงสัยไหม? ทำไมหลายโปรเจกต์ AI ในไทย ถึงไม่เคย Scaleอ่านเพิ่มเติม "10 ข้อศิลปะการปรับปรุง AI Products แบบ 100x"
My 2022 Achivements
Symbols meaning ✅ Already Achieved🔜 In Progress⛔ Low Prอ่านเพิ่มเติม "My 2022 Achivements"
🍌 รีวิว Web For Impact รุ่นที่ 4 🐣

ทักษะที่ไม่คิดว่าจะมีประโยชน์มากขนาดนี้ ! ใช่ครับฟังไม่อ่านเพิ่มเติม "🍌 รีวิว Web For Impact รุ่นที่ 4 🐣"
ตำแหน่งอยู่ไม่นาน ตำนานอยู่ตลอดไป

ตำแหน่งอยู่ไม่นาน ตำนานอยู่ตลอดไป ! 🙈กับการตั้งชื่อ "Viอ่านเพิ่มเติม "ตำแหน่งอยู่ไม่นาน ตำนานอยู่ตลอดไป"
เริ่มต้นทำ Mini Project ด้วย Julia DataFrame

Julia DataFrame คืออะไร Julia DataFrame เป็น Library จัอ่านเพิ่มเติม "เริ่มต้นทำ Mini Project ด้วย Julia DataFrame"
หัวข้อออกสอบ Data Scientist

ครั้งแรกที่แอดสัมภาษณ์งาน ก็นานมาแล้ว 🍭สมัยก่อนอาจจะไม่อ่านเพิ่มเติม "หัวข้อออกสอบ Data Scientist"
MLOps Summit เข้าฟังฟรี

แนะนำงาน MLOps Summit เข้าฟังฟรี ❤️🐣MLOps Day 2 Summit:อ่านเพิ่มเติม "MLOps Summit เข้าฟังฟรี"
Deploy ML model ด้วย MLEM
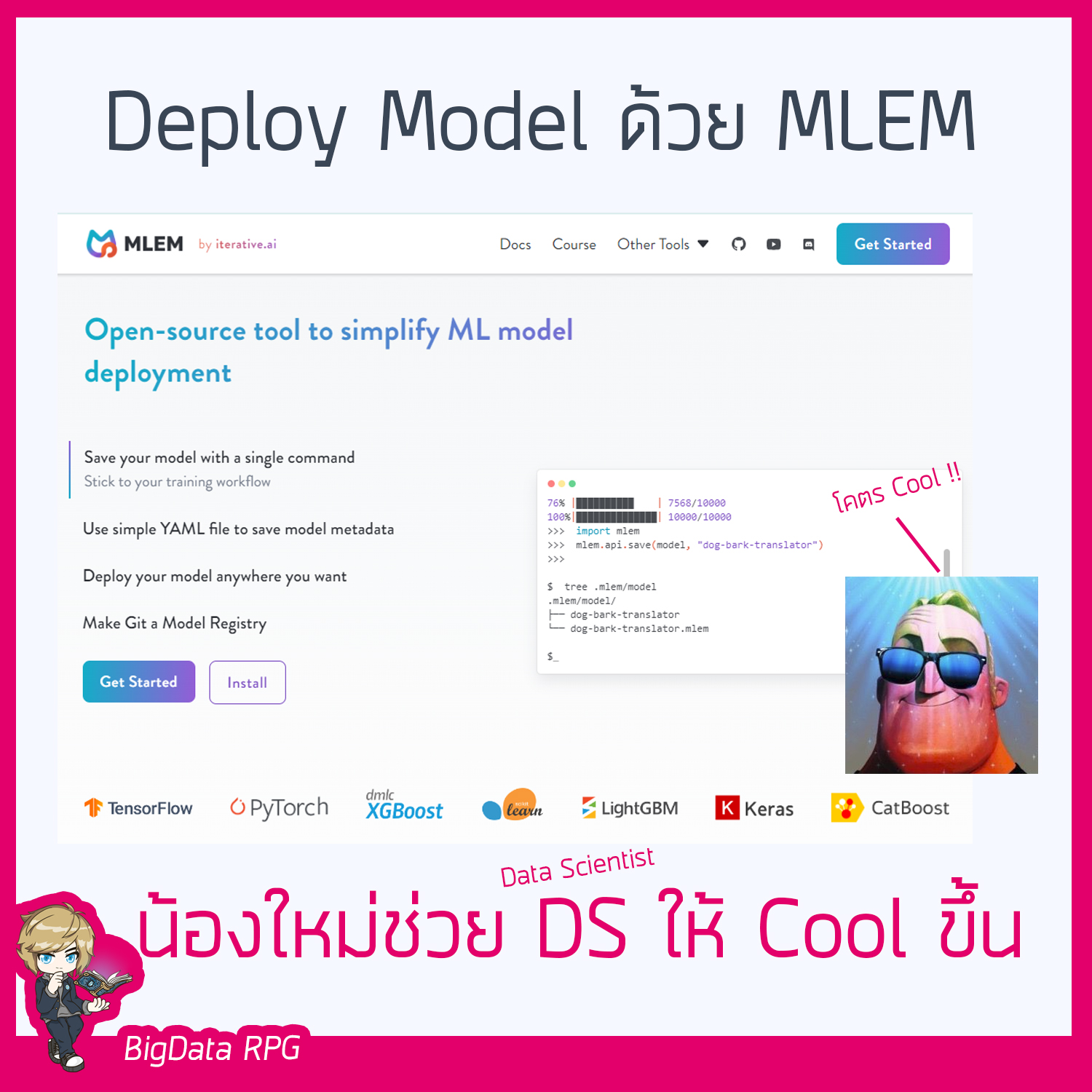
Deploy ML model ด้วย MLEM ❤️น้องใหม่ ที่ช่วยให้งาน DS งอ่านเพิ่มเติม "Deploy ML model ด้วย MLEM"
เรียน ML/RL ฟรี โดย AWS

เรียน ML และ RL ฟรี โดย AWS ! ❤️🚀จากโครงการ AWS DeepRacอ่านเพิ่มเติม "เรียน ML/RL ฟรี โดย AWS"
Airflow คืออะไรเอ่ย

Tools ยอดนิยมของชาว Data Engineersที่เหล่า Data Scientiอ่านเพิ่มเติม "Airflow คืออะไรเอ่ย"
