
"ถ้าคุณเติม Missing Value ผิดวิธีมันจะกลายเป็นการเพิ่ม อ่านเพิ่มเติม "Missing Values คืออะไร"
พาเพื่อนๆมารู้จักกับ Feature Stores
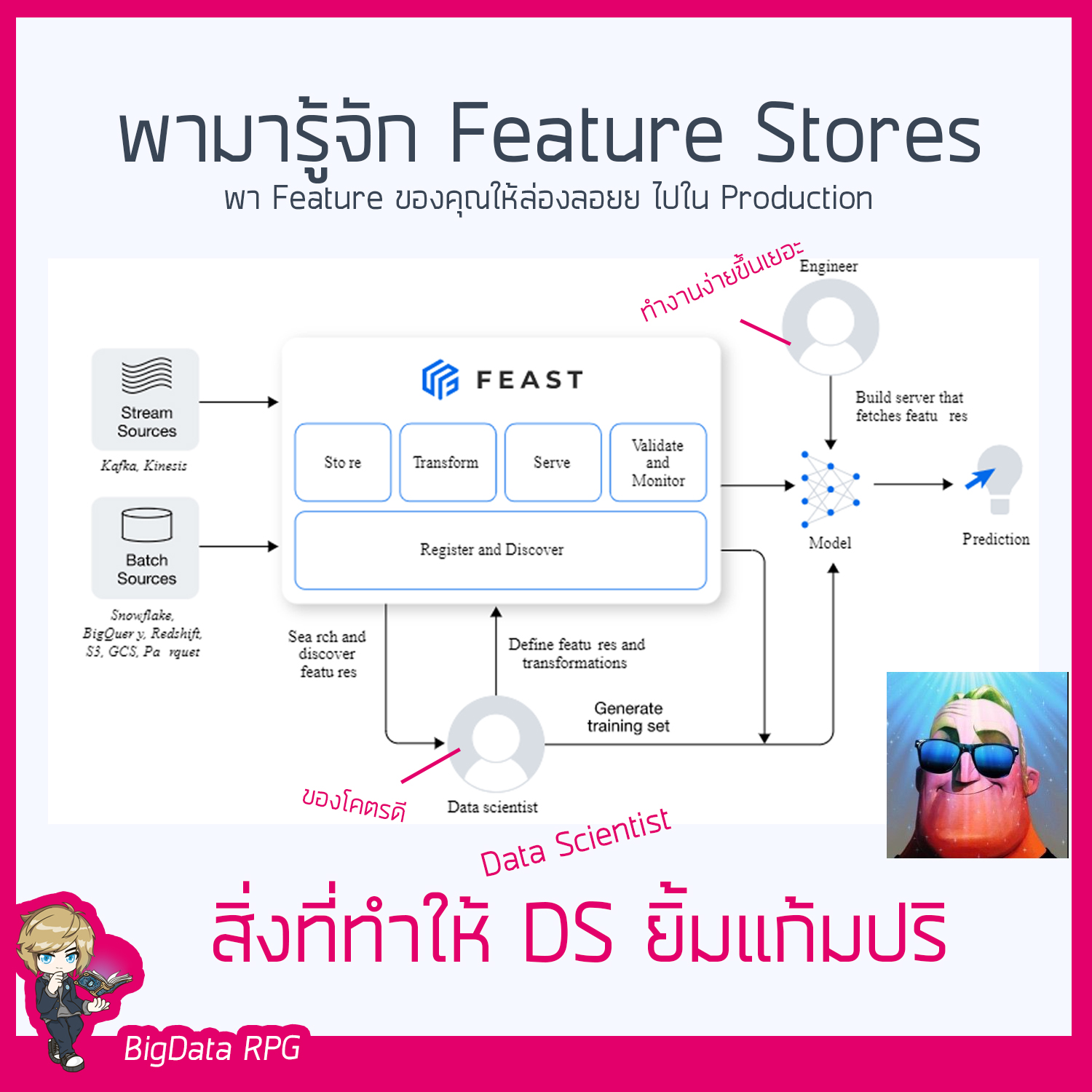
พาเพื่อนๆมารู้จักกับ Feature Stores 👷♀👩🔬เพราะ Model Mอ่านเพิ่มเติม "พาเพื่อนๆมารู้จักกับ Feature Stores"
ชวนดู Data@Scale

คืนนี้ชวนอดนอนชม Data@Scale 🌹 (5ทุุุ่ม แจกัน)Conferenceอ่านเพิ่มเติม "ชวนดู Data@Scale"
เริ่มต้นศึกษา MLOps

👷♀ แนะนำช่องเริ่มต้นศึกษาสาย MLช่องนี้เลย DataTalksCluอ่านเพิ่มเติม "เริ่มต้นศึกษา MLOps"
Gimmick น่ารั้กๆของ Kaggle

หลังจากเรา Summit ผลลัพธ์ของการแข่งขันKaggle จะพาเราไปชอ่านเพิ่มเติม "Gimmick น่ารั้กๆของ Kaggle"
Meta เปิดสอนทักษะ SWE ฟรี

Meta หรือ Facebook ชื่อเก่า เปิดสอนทักษะ ฟรี 😳โดย Meta อ่านเพิ่มเติม "Meta เปิดสอนทักษะ SWE ฟรี"
แนะนำโจทย์ Kaggle Community สำหรับเริ่มต้น

Kaggle แนะนำโจทย์ Community ที่น่าสนใจเล่นมาลองเก็บเลเวอ่านเพิ่มเติม "แนะนำโจทย์ Kaggle Community สำหรับเริ่มต้น"
Kaggle – AI4Code Challenge

สายล่าเงินรางวัลห้ามพลาด💸ครั้งนี้ Kaggle ตั้งเงินรางวัลอ่านเพิ่มเติม "Kaggle – AI4Code Challenge"
Google Cloud Applied ML Summit

ถึงคราวของ Events จาก GCP อีกแล้ว ❤️Google Cloud Applieอ่านเพิ่มเติม "Google Cloud Applied ML Summit"
เริ่มต้น Bayesian ด้วยเล่มนี้

ชวนอ่านหนังสือน่ารั้กๆเบาๆกันบ้าง ❤️🐣เพื่อนๆที่ชอบสาย Bอ่านเพิ่มเติม "เริ่มต้น Bayesian ด้วยเล่มนี้"
